By: Suman Kanuganti
Distributed Small Language Models power memory-based, hyper-personalized voice and text experiences with sub-500ms response times and up to 40× better token economics than centrally hosted LLMs
More than 3 billion phone calls happen each day in the United States, about three times the volume of Google searches. Most days are steady with predictable traffic. But there are exceptions where predictable and unpredictable bursts happen. Telephone Tuesday is an example of a predictable burst. Each year on the Tuesday following Labor Day, traffic spikes by 30–50%, making it a major outlier that telecom infrastructure must accommodate. In other scenarios, such as natural disasters or breaking news, unpredictable bursts may happen. Telecom infrastructure must accommodate these events too.
Earlier in my career at Intuit, I worked on similar system resiliency issues, ensuring that our TurboTax systems would meet performance requirements precisely when the system was under maximum load, typically in the weeks leading up to Tax Day. I see the same patterns emerging in AI, only at a much greater scale, velocity, and cost. As AI becomes even more embedded in society over the coming years (smart homes, humanoids, connected vehicles, and new use cases), we can expect repeatable peaks of traffic, predictable and unpredictable bursts, and high expectations for consistent performance.
Serving this demand efficiently will be foundational. Telecom companies are best positioned to do it, with NVIDIA’s AI Grid as the framework and Personal AI’s Memory Platform, including our memory-based Small Language Models, to unlock use cases that are better, faster, and cheaper.
Consider the AI-of-Things mentioned above: smart homes, humanoids, and connected vehicles. Each of these markets are growing rapidly, each is unique, and each needs connectivity. They also share another need: memory.
Memory must be intelligently created, stored, and retrieved. This is important to creating delightful user experiences that bring differentiated value. Without it, AI is stateless, transactional, and impersonal. The default market solution for memory is currently based on context; that is, simulating memory by retrieving and feeding context to LLMs. This works up until a certain point, but starts rapidly losing precision as the memory scales, and is far more slow and costly than our approach.
This is why we built the Personal AI Memory Platform: an architecture designed for operators leveraging NVIDIA's AI Grid framework, with flexible deployment options that leverage both distributed edge and centralized environments. This architecture is built with memory at its core, flexible by design to serve many different use cases.
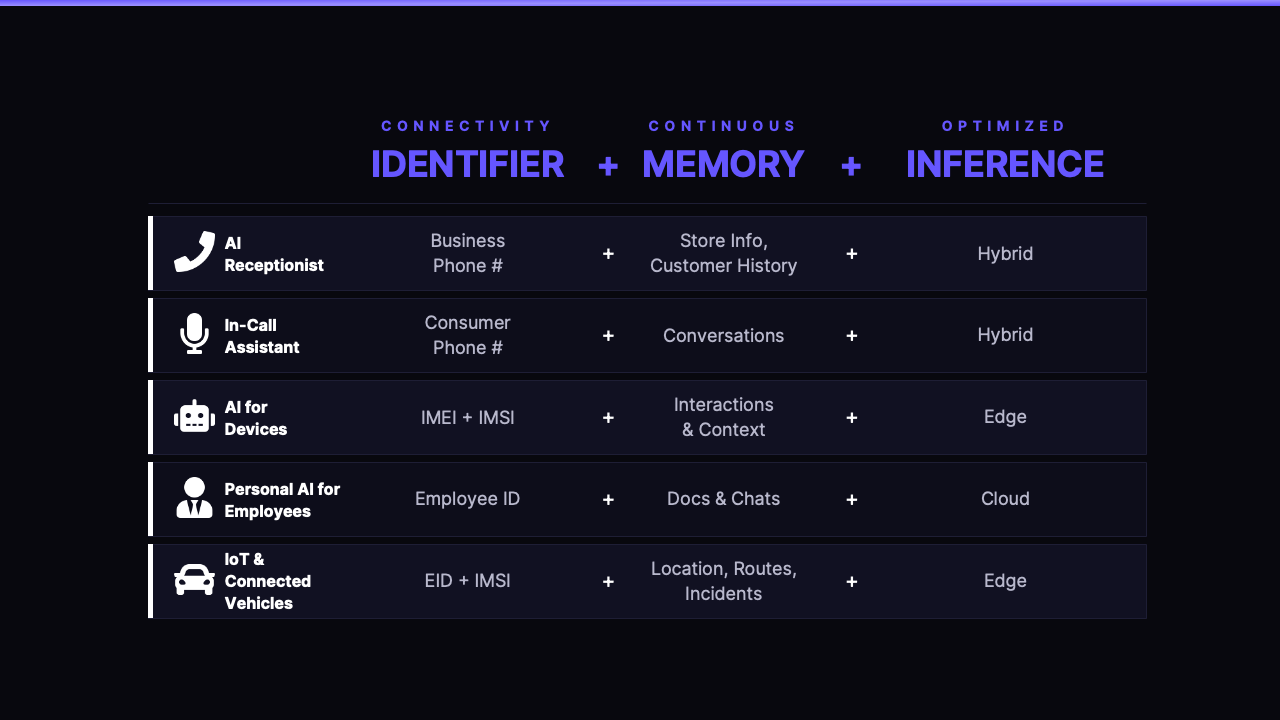
Products powered by our Memory Platform typically involve three core capabilities working in unison: Connectivity Identifier, Continuous Memory, and Optimized Inference.
At GTC 2026, NVIDIA introduced the AI Grid, the framework for distributing AI inference workloads across infrastructure rather than concentrating them in centralized cloud data centers. The thesis is straightforward: Large Language Models require massive GPU clusters in centralized facilities, creating bottlenecks and network delays that result in poor GPU utilization and user experience. Smaller, specialized models deployed across a distributed grid can serve the same workloads faster, more reliably, and at lower cost, particularly under high concurrency.
Personal AI partnered with Comcast and NVIDIA to test this thesis in a controlled environment, running Personal AI's SLMs across various hosting configurations and concurrency levels.

The results validated our thesis. Under heavy traffic, Personal AI's SLM running across a distributed AI Grid maintained response times well within the threshold for natural conversation, even during bursts. To summarize our key findings:
Speed and efficiency are necessary pre-conditions for natural AI experiences at scale, but they alone are not enough. A fast response without memory is just a faster generic answer. The real unlock is pairing distributed inference with continuous memory, so that every interaction is not only fast but meaningfully informed. That is what the Personal AI Memory Platform is designed to deliver.
NVIDIA's technical blog on the results of benchmarking Personal AI can be found here and Comcast's technical blog is expected to be published this week. If you are interested in discussing the results in more detail, you can contact us here.
Telecom operators are uniquely positioned to deliver this distributed inference and AI-of-Things and own it. They control the telephone numbers and service identifiers for connected devices, the identity anchor that every customer calls. They operate distributed infrastructure with deterministic low latency that no centralized cloud can match. They have millions of businesses already in-contract. And with NVIDIA's AI Grid, they now have the compute framework to embed accelerated hardware directly into their networks.
The cloud and mobile eras saw telcos primarily as infrastructure providers while hyper-scalers and OEMs captured the software value. AI presents a unique opportunity for telcos to vertically integrate the future stack, reclaiming value by combining their backbone with intelligent services.
Personal AI provides the intelligence layer: persistent memory per entity, domain-tuned Small Language Models that run 40x cheaper than hosted LLMs, and a telephony-native voice stack that delivers fast responses. Any use case that fits the Identifier + Memory + Inference structure — from AI receptionists to in-call assistants to connected devices — can be built with our Memory Platform. The telco owns the product, owns the customer, and owns the brand.
On Telephone Tuesday 2026, millions of calls will flood the network. The HVAC shop without memory-based AI will watch its system buckle — responses lagging, context lost, customers hanging up. The shop down the street, running an AI Receptionist from their telecom provider, powered by Personal AI and the AI Grid, will handle every call at a fraction of the cost and with consistency.
The qualitative difference is memory. When the homeowner whose cooling system failed in August calls back, the AI receptionist already knows. It recalls the service history, the preferred appointment times, the specific equipment in the home. The conversation is personalized, efficient, and feels human.
Now scale that across every small business, every enterprise, every consumer touchpoint on a telco's network. The receptionist is just the first application. The same platform — same identifier, same memory, same inference — powers in-call assistants, AI for devices, employee AI, connected vehicles, and more.
The telco that seizes this opportunity will own the largest market in AI.

